"In 2023, the landscape of generative AI has undergone a revolutionary expansion, pioneered by the remarkable capabilities of GPT and ChatGPT. Amazon and AWS are at the forefront of this transformation, seamlessly integrating GPT, advanced transformer technologies, and a proprietary array of generative AI models to enhance their diverse portfolio of innovative solutions."
"Comprehensive Guide to Amazon's Suite of Advanced AI and ML Services"
• Amazon Comprehend: This service handles natural language processing and text analytics. You can feed it various types of content like social media posts, emails, web pages, documents, transcripts, and medical records for analysis.
• Amazon Transcribe: This service converts speech to text. It features speaker and channel identification, language detection, and custom vocabularies. Use cases include analyzing calls, medical transcription, and creating subtitles.
• Amazon Polly: A neural text-to-speech service offering a range of voices and languages. It supports lexicons, Speech Synthesis Markup Language (SSML), and speech marks.
• Amazon Rekognition: Computer vision technology that identifies objects and scenes, moderates images, analyzes faces, recognizes celebrities, compares faces, detects text in images, and analyzes videos.
• Amazon Forecast: A fully managed service that uses machine learning to deliver highly accurate forecasts. It works with any time series data, using 'AutoML' to select the best model for you.
• Forecasting Algorithms:
CNN-QR: Convolutional Neural Networks for Quantile Regression.
DeepAR+: A recurrent neural network-based model.
Prophet: Non-linear trends with seasonality.
NPTS: Non-parametric time series forecasting.
ARIMA: Autoregressive Integrated Moving Averages.
ETS: Exponential Smoothing models.
• Amazon Lex: The technology behind Alexa. A natural-language chatbot engine that integrates with the AWS Mobile SDK and Facebook Messenger.
• Amazon Personalize: A recommender system that's fully managed and accessed via API. It provides real-time or batch recommendations for new users and items, contextual suggestions, and trending items, complete with business rules and filters.
• Amazon Monitron: An end-to-end system for monitoring industrial equipment and predictive maintenance.
• TorchServe: A model serving framework designed for PyTorch.
• AWS Neuron: An SDK for optimizing machine learning models for faster inference.
• AWS Panorama: Brings computer vision to the edge, allowing you to add these capabilities to your existing IP cameras.
• AWS DeepComposer: An AI-powered keyboard created mainly for educational purposes.
• Amazon Fraud Detector: Upload your historical fraud data and use the API to protect your online applications.
• Amazon CodeGuru: Automated code reviews that highlight inefficient code. It provides specific recommendations powered by machine learning and supports Java and Python.
• Contact Lens for Amazon Connect: Designed for customer support call centers, this tool enables searching through calls/chats, sentiment analysis, automatic categorization, and theme detection to identify disorders and emerging issues.
• Amazon Augmented AI (A2I): Facilitates human review of machine learning predictions by building workflows for analyzing low-confidence predictions.
• Amazon Bedrock: An API for using foundation models. It's serverless and fine-tunes models with labeled examples stored in S3. Your data stays within your VPC, encrypted, and is only used for your models.
• Amazon CodeWhisperer: Provides real-time code suggestions. Just write a comment about what you want to do, and it offers solutions. It also analyzes code for vulnerabilities, with all transmissions secured by TLS.
SageMaker Workflow:
• Deploy the model and monitor results in a live environment.
• Gather, clean, and prepare your dataset.
• Train the model and assess its performance.
• Then, repeat from step 1 as needed.
SageMaker is designed to streamline the entire machine learning process.
Using SageMaker with Docker:
Essentially, SageMaker relies on Docker containers for running machine learning models. Each model is packaged into a Docker container, which is then stored in Amazon ECR (Elastic Container Registry). To build these containers, you start with a Dockerfile to create an image, which is then saved in a repository within Amazon's ECR service.
Decoding Transformers: From RNNs to Generative Pre-trained Transformers in AI
GPT, developed by OpenAI, is a notable name in the AI world and is seen as a competitor to Amazon. As such, we don't find ChatGPT or GPT-4 within Amazon's ecosystem, but earlier models like GPT-2 and GPT-3 are available.
Origins of Transformers
Transformers have evolved from earlier neural network models like RNNs and LSTMs, which were quite good at deciphering meaning from text sequences. RNNs, with their feedback loops, are particularly adept at handling sequences of data.
The real game-changer with transformers is the 'Self-Attention' mechanism. It learns the relationships between words, significantly affecting the contextual meaning of each word or 'token' in a sentence. Self-Attention is excellent at managing word order variations and grasping word relationships.
A key feature of transformers is their ability to 'self-attend' and process computations in parallel, allowing for training on larger datasets. In practice, this means each word in a sentence is considered in relation to every other word, creating a weighted average that defines its context.
Masked Self-Attention is a technique to stop the model from 'seeing' future words during training, which is essential for tasks like translation. 'Multi-Headed Self-Attention' is where it gets interesting: by dividing the attention mechanism into multiple 'heads', transformers can process different parts of the sentence simultaneously.
Uses of Transformers
These models are versatile and have a range of applications, including chatbots, question-answering systems, text classification like sentiment analysis, recognizing named entities, summarizing texts, translating languages, generating code, and creating new text.
GPT Explained
GPT stands for 'Generative Pre-trained Transformer'. It's a decoder-only model, which means it focuses on generating the next word in a sequence. It doesn't work with traditional inputs and outputs; instead, it continuously predicts the next word. This approach enables the model to learn language patterns from vast amounts of text without specific labeling.
The output process involves the model's decoders producing a vector that, when combined with token embeddings, generates a set of probabilities (logits) for the next word. By adjusting the 'temperature', you can introduce randomness into the selection process instead of always choosing the most likely word.
Fine-Tuning Transformers
Transfer learning with transformers involves using additional training data, selectively freezing some layers while retraining others, or adding a new layer on top of the pre-trained model. This way, you can tailor the model for specific tasks like classification or others.
Implementing GPT and BERT with LLMs:
A Guide to Tokenization, Positional Encoding, and Self-Attention Visualization.Understanding how large language models function is straightforward. We start by importing a 'pipeline' from the Transformers library and then input some text. These models, like the IMDB movie reviews dataset, can be fine-tuned for specific tasks.AWS introduces what are known as 'foundation models,' which provide flexibility and robustness, though they come with some complexity and cost.
Step 1: Importing Libraries
Initially, ensure the installation of the required libraries, followed by their importation. This includes libraries for numerical computations, data visualization, and the incorporation of BERT and GPT-2 models from the Transformers library by Hugging Face. For visualization purposes, bertviz is also utilized.
Step 2: Tokenization and Model Initialization
The BERT tokenizer and model are initialized to facilitate text tokenization and to elucidate the manner in which BERT interprets its inputs.Step 3: Positional Encoding Explanation
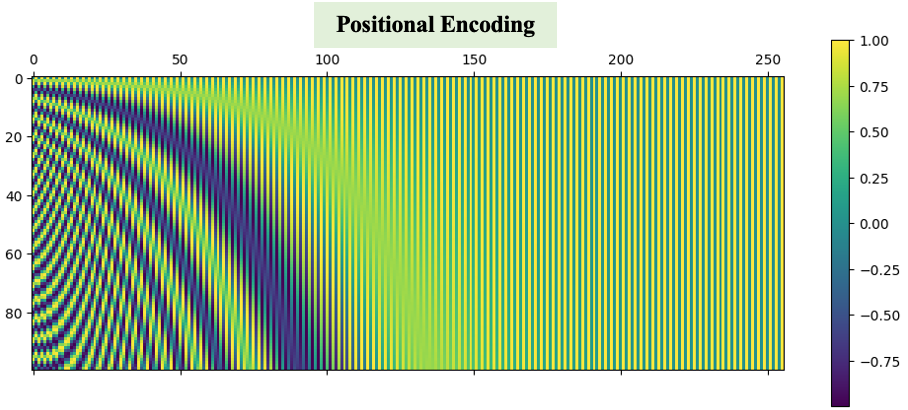
The significance of positional encoding is discussed, enabling the model to recognize the sequential arrangement of words within a sentence.
Step 4: Self-Attention Mechanism Visualization
Employing bertviz, the functionality of BERT's self-attention mechanism is illustrated, accentuating the interrelations among words in a sentence. link for visualization self-sttention with BERT model
Step 5: Generating Text with GPT-2
The process concludes with a demonstration of text generation using the GPT-2 model, which highlights its proficiency in producing coherent and contextually appropriate text based on a specified prompt.
These massive, pre-trained transformer models, such as GPT-n by OpenAI, supported by Microsoft, can be fine-tuned for particular tasks or adapted for new applications. OpenAI's GPT-n also powers a service product available on Microsoft's Azure. Open-source models like GPT-2 and GPT-J are readily accessible on AWS. BERT, a creation of Google, differs by being built on encoders rather than decoders. Unlike OpenAI, Google operates its services independently and does not integrate with AWS. For image generation, OpenAI's DALL-E, also backed by Microsoft, is a go-to model. On the other hand, Meta's LLaMA specializes in text generation, and 'Segment Anything' by Meta can be an alternative to DALL-E.
Amazon's AWS offers a suite of foundation models, including:
• Jurassic-2 from AI21Labs: Multilingual large language models focused on text generation.
• Claude from Anthropic: Designed for conversational AI.
• Stable Diffusion from Stability AI: Aimed at image and design creation.
• Amazon Titan: Specializes in text summarization and generation.
• Amazon SageMaker Jumpstart: Provides access to generative AI and models from
Hugging Face, such as Falcon, Flan, GPT-J, and stable diffusion, alongside Amazon Alexa's encoder/decoder multilingual capabilities.
# Installing the necessary libraries
!pip install git+https://github.com/huggingface/transformers
!pip install jupyterlab ipywidgets bertviz xformers evaluate matplotlib
# Importing libraries
import numpy as np
import matplotlib.pyplot as plt
from transformers import BertModel, BertTokenizer, pipeline
from bertviz import model_view
# Tokenization and Model Setup for BERT
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertModel.from_pretrained(model_name)
# Tokenizing a sample text
sample_text = "I live in Montreal and I like this city."
tokenized_output = tokenizer(sample_text)
print("Tokenized IDs:", tokenized_output["input_ids"])
print("Tokens:", tokenizer.convert_ids_to_tokens(tokenized_output["input_ids"]))
# Positional Encoding Function
def positional_encoding(num_tokens, dimensions, scaling_factor=10000):
"""
Calculates the positional encoding for a given number of tokens and dimensions.
Args:
- num_tokens: Number of tokens in the sequence.
- dimensions: Dimensions of the model.
- scaling_factor: Scaling factor used in the encoding calculations.
Returns:
- A numpy array containing the positional encodings for each token.
"""
position = np.zeros((num_tokens, dimensions))
for i in range(num_tokens):
for j in range(0, dimensions, 2):
position[i, j] = np.sin(i / (scaling_factor ** (j / dimensions)))
position[i, j + 1] = np.cos(i / (scaling_factor ** ((j + 1) / dimensions)))
return position
# Visualizing Positional Encoding
pos_encoding = positional_encoding(100, 256)
plt.figure(figsize=(10, 8))
plt.matshow(pos_encoding, cmap='viridis')
plt.colorbar()
plt.title("Positional Encoding")
plt.xlabel("Dimensions")
plt.ylabel("Token Position")
plt.show()
# Self-Attention Visualization with BertViz
sample_text = "I live in Montreal and I like this city."
model_view(model, model_name, tokenizer, sample_text, display_mode="dark", head=9)
model_view(model, model_name, tokenizer, sample_text, display_mode="light", head=9)
# Text Generation with GPT-2
gpt2_generator = pipeline('text-generation', model='gpt2')
print(gpt2_generator("I enjoy hiking and running.", max_length=20, num_return_sequences=3))
print(gpt2_generator("Montreal is a good place for sports.", max_length=50, num_return_sequences=5))
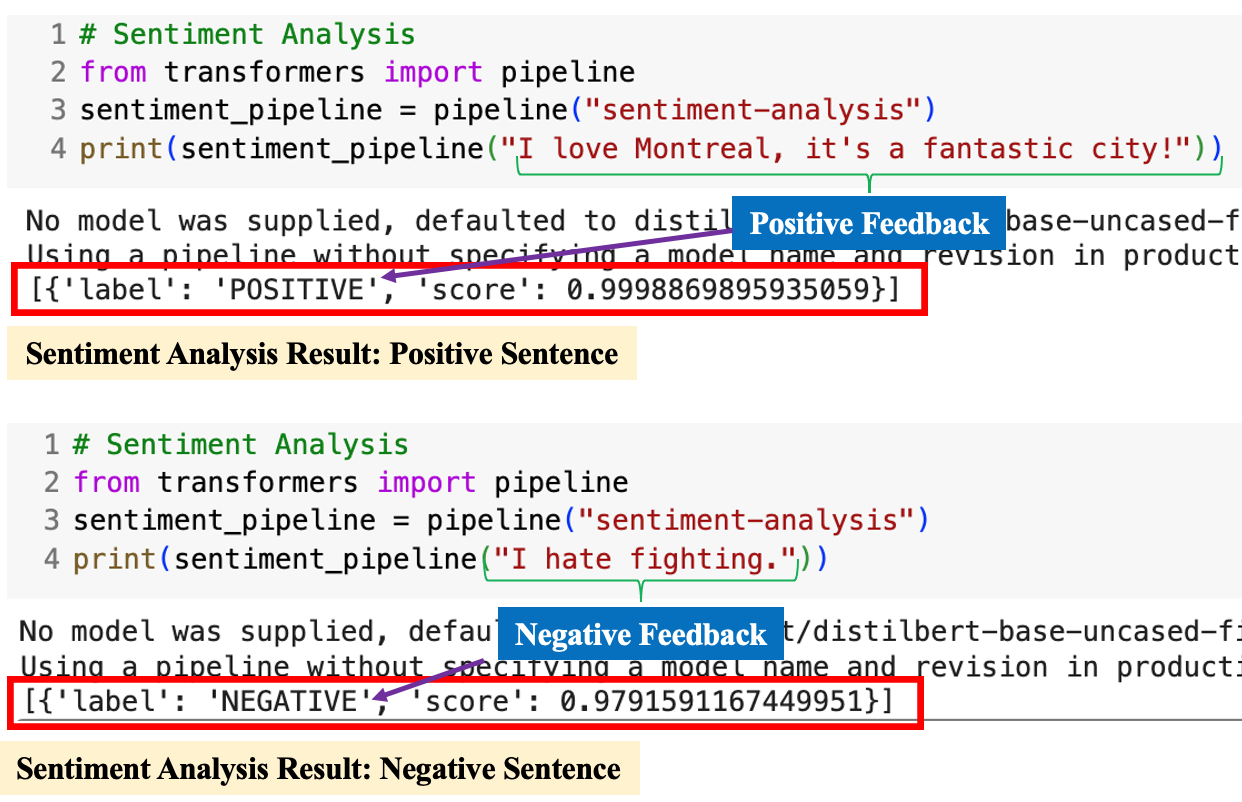
# Sentiment Analysis
##postive result
from transformers import pipeline
sentiment_pipeline = pipeline("sentiment-analysis")
print(sentiment_pipeline("I love Montreal, it's a fantastic city!"))
# Sentiment Analysis
##negative result
from transformers import pipeline
sentiment_pipeline = pipeline("sentiment-analysis")
print(sentiment_pipeline("I hate fighting."))
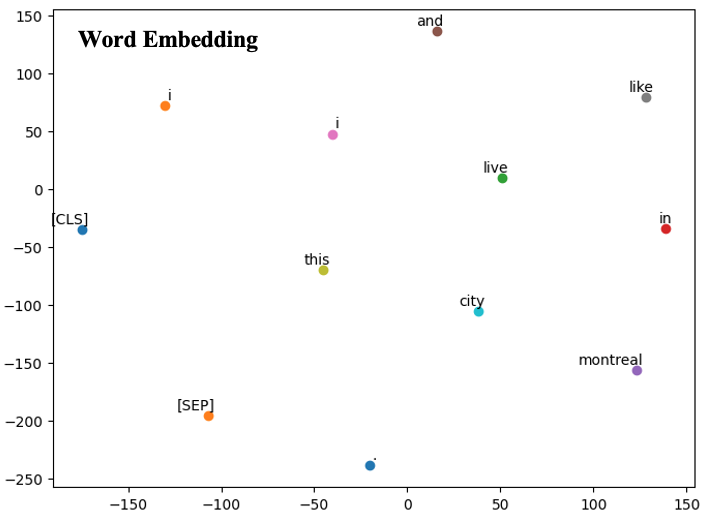
#Word Embedding visualization
## Extract embeddings
tokenized_text = tokenizer_bert("I live in Montreal and I like this city.", return_tensors="pt")
with torch.no_grad():
outputs = model_bert(**tokenized_text)
embeddings = outputs.last_hidden_state.squeeze().numpy()
## Use t-SNE for dimensionality reduction
tsne_model = TSNE(perplexity=10, n_components=2, init='pca', n_iter=2500, random_state=23)
new_values = tsne_model.fit_transform(embeddings)
## Plotting
df = pd.DataFrame(new_values, columns=['x', 'y'])
df['token'] = tokenizer_bert.convert_ids_to_tokens(tokenized_text['input_ids'].squeeze().tolist())
plt.figure(figsize=(8, 6))
for i, token in enumerate(df['token']):
plt.scatter(df.iloc[i]['x'], df.iloc[i]['y'])
plt.annotate(token, xy=(df.iloc[i]['x'], df.iloc[i]['y']), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()