The project focuses on Text-to-Image Generation, leveraging the cutting-edge "Diffusion Model v0.8 by Stability AI" to transform textual prompts into detailed images. Key Steps for Implementation:
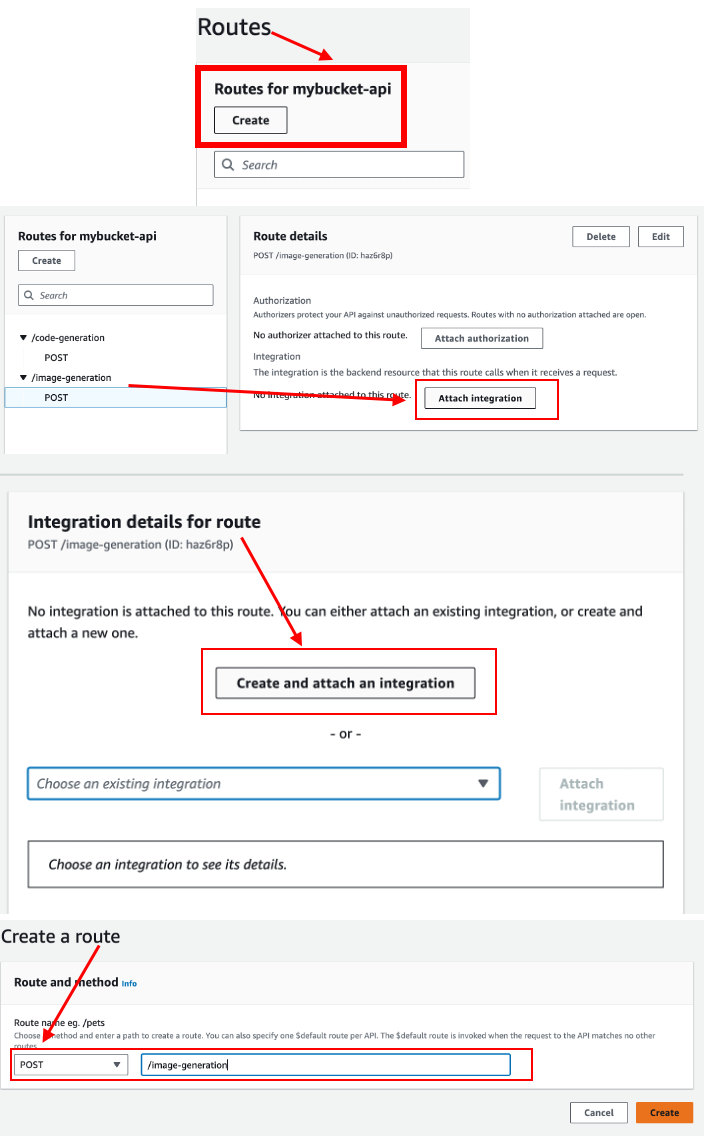
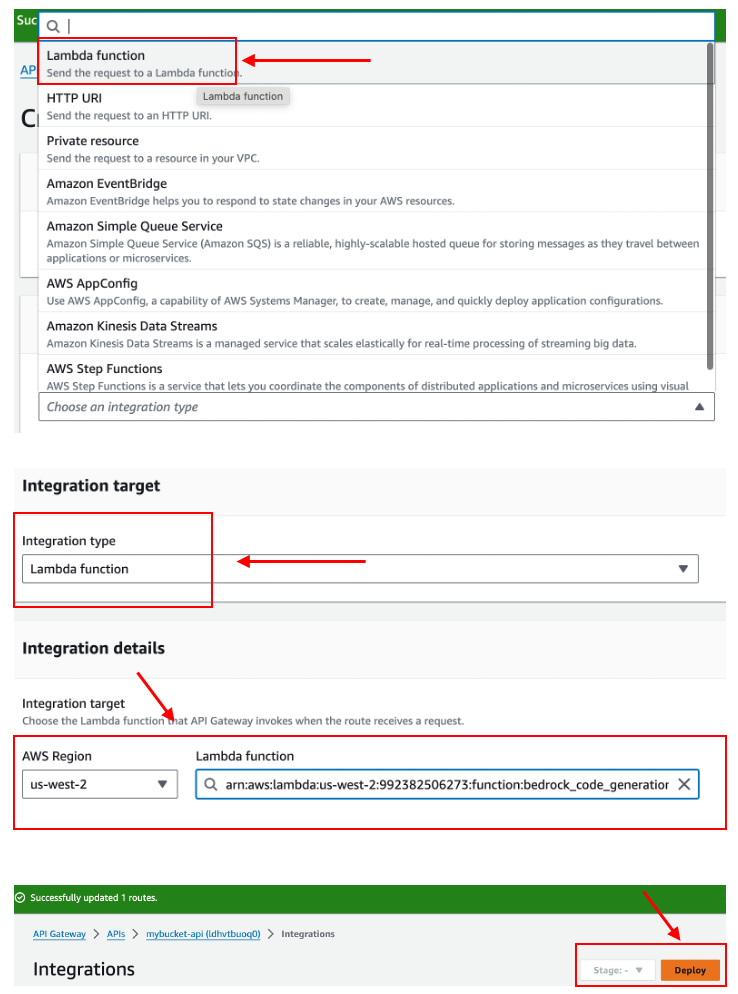
• API Gateway Configuration: Establish a new route within the API Gateway to interface with our service. This setup mirrors our previous projects, with the crucial distinction of integrating the "Diffusion Model v0.8" as the backend model.
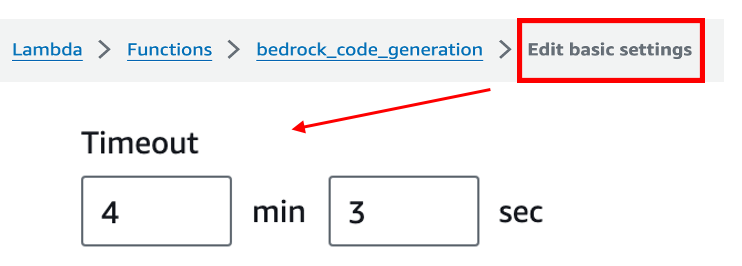
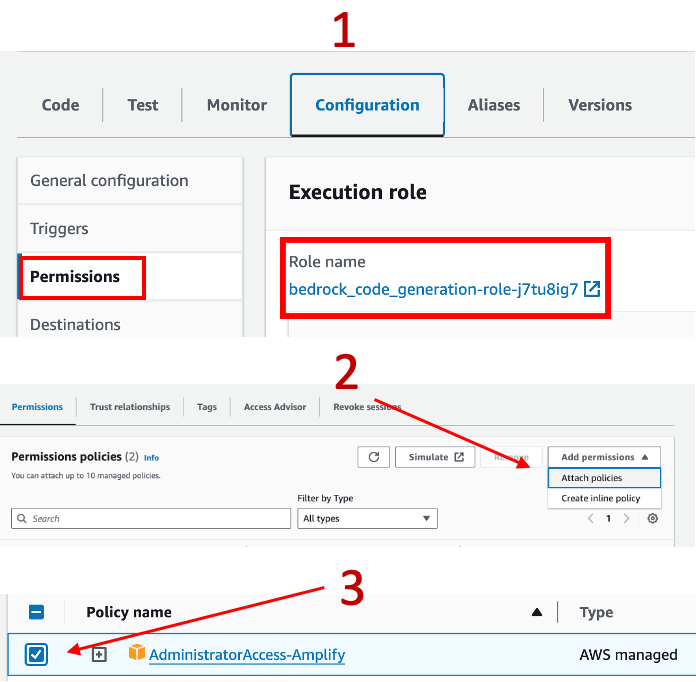
• Lambda Function Creation: Implement a Lambda function tailored for this project. It's vital to adjust the timeout settings beyond the default three seconds to prevent premature termination of the process and ensure it has administrator-level access for initial setup. Post-deployment, it's imperative to adhere to the principle of least privilege by assigning only the necessary IAM permissions to users, minimizing potential security risks.
Coding and Integration:
• Unlike previous projects, this initiative does not require pre-processing functions. We start directly with the 'lambda-handler', which processes the input event and context. The core functionality revolves around parsing the event message, which serves as the model prompt (e.g., "generate a cat eating ice cream").
• We then initialize the Bedrock client for backend interactions and an S3 client for storing the generated images in AWS S3, ensuring durable and accessible storage.
• Payload Structure and Model Configuration:
• The payload for the stable diffusion model differs slightly, requiring specific structuring. A critical parameter, the 'CFG_scale', determines the influence of the textual prompt on the output image, allowing for finer control over the generation process.
API Endpoint and Image Generation:
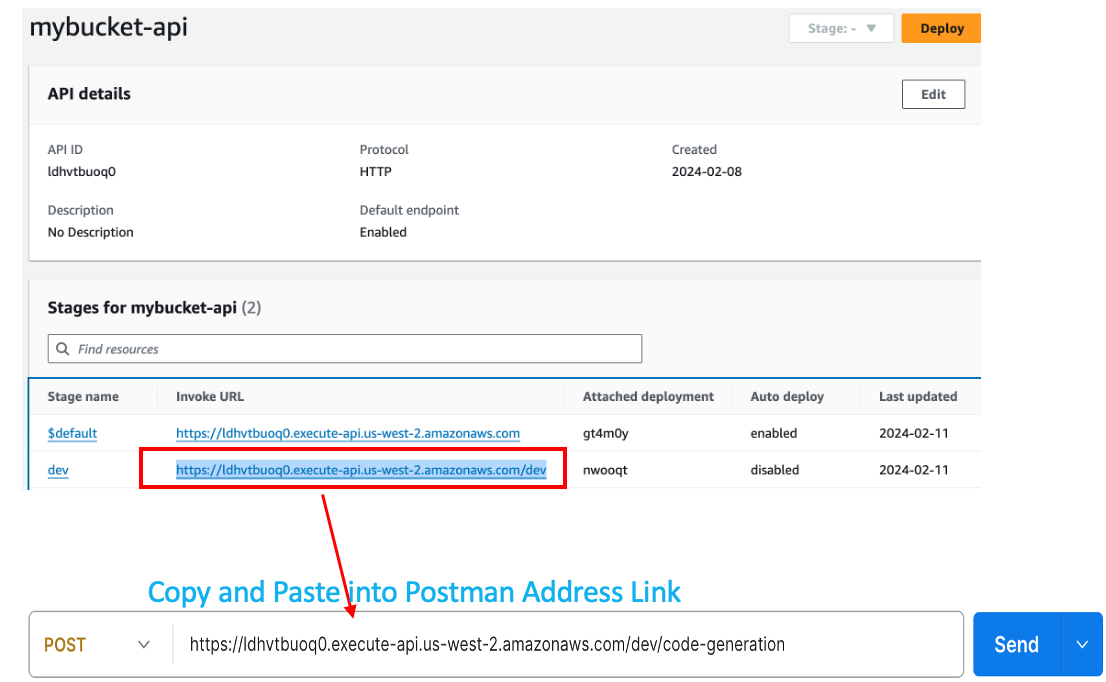
• The next phase involves setting up an API route for our lambda_function, culminating in the creation of an image generation endpoint. This enables users to interact with the model via a straightforward API call.
• To enhance the quality of generated images, it is advisable to experiment with the model's 'step size', potentially increasing it beyond 100 steps. Such adjustments can significantly improve the visual fidelity and detail of the output, aligning with project objectives.
• In summary, by carefully configuring the API gateway, Lambda function, and model parameters, and by employing robust coding practices, this project not only achieves Text-to-Image generation but sets a foundation for optimizing image quality through strategic parameter tuning.
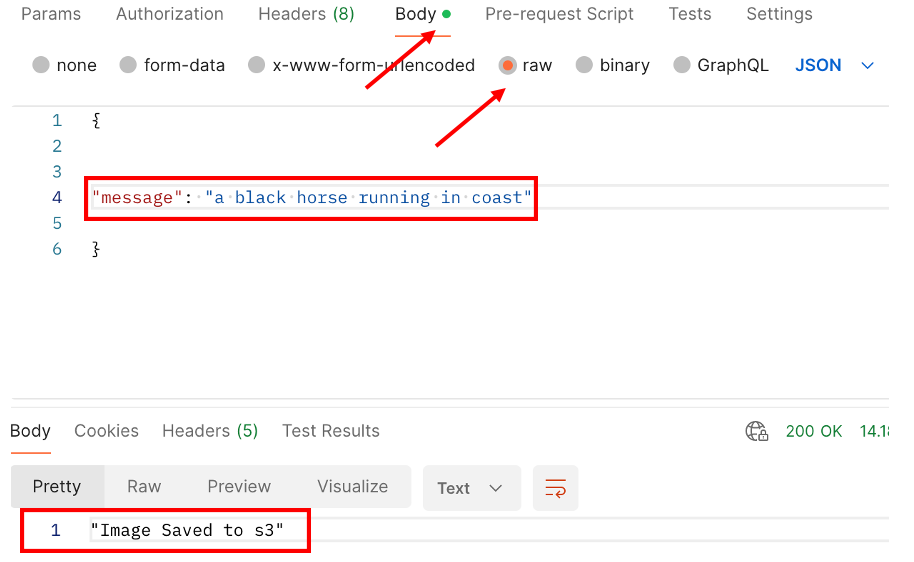
Generated Image from Text "Running a horse in coast"

if you don't have any authorization that protects your endpoint, delete API route immediately to prevent public access to your lambda functiuon.
Code Description:
• Imports and Dependencies:
json: For parsing JSON strings.
boto3: The Amazon Web Services (AWS) SDK for Python, used to interact with AWS services like Amazon S3 and the custom model service.
botocore: A low-level interface to a growing number of Amazon Web Services, used here for configuring the retry behavior and timeout settings.
datetime: For generating a timestamp to uniquely name the output files.
base64: For decoding the base64-encoded image data received from the model.
•Lambda Handler Function:
Named lambda_handler, it is the entry point for AWS Lambda to execute the code in response to an event, such as an HTTP request from API Gateway.
• Extracting Input Data:
The function begins by extracting input_data from the event object, which contains data sent by the API Gateway. It specifically looks for a 'message' key in the JSON payload, which is expected to contain the text prompt for image generation.
• Setup AWS Clients:
Initializes an AWS client for a custom model service named "bedrock-runtime" in the "us-west-2" region, with specific configuration for read timeout and retry attempts. This service is presumably a placeholder for a real service that generates images. Initializes an Amazon S3 client for storing the generated images.
• Image Generation Parameters:
Defines parameters for generating an image, including details about the prompt (input_text), configuration settings like cfg_scale for adjusting the prompt's impact, a seed for reproducibility, and the number of steps for the generation process.
• Invoking the Model:
Calls the custom model with the prepared parameters to generate an image. This step is critical as it interacts with a presumably complex machine learning model to produce an image based on the provided text prompt.
• Processing the Model Response:
Extracts the encoded image string from the model's response, decodes it from base64 to binary data, preparing it for storage.
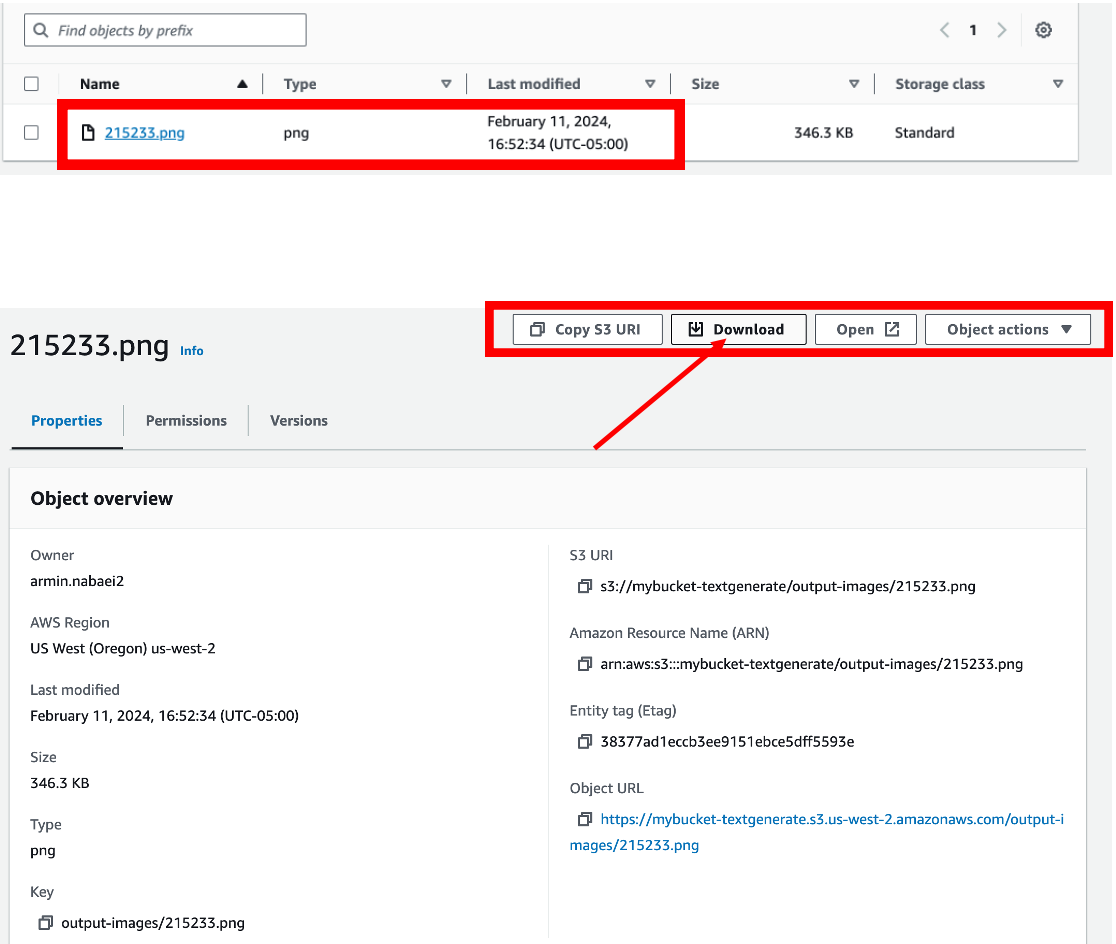
• Saving the Image to S3:
Defines a bucket name (mybucket-textgenerate) and a unique key for the image based on the current timestamp, ensuring each generated image is saved with a unique filename. Uploads the decoded image to the specified S3 bucket using the put_object method.
• Response:
Returns a success status code (200) and a message indicating the image has been saved to S3, signifying the end of the function's execution.
import json
import boto3
import botocore
from datetime import datetime
import base64
def lambda_handler(event, context):
#we're getting data from API gateway
input_data = json.loads(event['body'])
#the message is basically going to be the prompt to the model
input_text = input_data['message']
image_generator = boto3.client("bedrock-runtime",region_name="us-west-2",config = botocore.config.Config(read_timeout=300, retries = {'max_attempts':3}))
#we also need the S3 client to saving the final images to S3
s3 = boto3.client('s3')
generation_params = {
"prompt_details":[{f"text":input_text}],
#CFG_scale is how much the prompt should affect the final output
"cfg_scale":10,
"generation_impact": 12,
"seed":42,
#set the seed so it's not fully random
#and we could somehow reproduce it if we wanted to
"steps":120
}
model_response = image_generator.invoke_model(body=json.dumps(generation_params),modelId = 'stability.stable-diffusion-xl-v0',contentType = "application/json",accept = "application/json")
#once we have the response, we need to extract the image content and decode it.
model_output = json.loads(model_response.get("body").read())
encoded_image_str = model_output["artifacts"][0].get("base64")
image = base64.decodebytes(bytes(encoded_image_str ,"utf-8"))
#define our S3 bucket to upload image to it
bucket_name = 'mybucket-textgenerate'
time = datetime.now().strftime('%H%M%S')
s3_key = f"output-images/{time}.png"
s3.put_object(Bucket = bucket_name, Key = s3_key, Body = image, ContentType = 'image/png')
return {
'statusCode': 200,
'body': json.dumps('Image Saved to s3')
}