Advancing Natural Language Understanding: Dynamic Embeddings and AWS Integration
Let’s dive into why models like ChatGPT stand out compared to traditional algorithms:
Old-school methods like Word2Vec and GloVe assign a single, static vector to each word. However, advanced models such as Elmo, Bert, GPT, and others within Bedrock produce dynamic embeddings. This means the meaning of a word can change based on its context, capturing subtleties and managing words with multiple meanings, also known as polysemy.For example, consider the OpenAI tokenizer platform (https://platform.openai.com/tokenizer).
It shows that a word doesn't always correspond to a single token. Sometimes, it's represented by several tokens, emphasizing the complexity and richness of language. This text keeps the explanation straightforward and avoids technical jargon, making it more accessible to readers who may not be familiar with NLP concepts.

Your data is safe with us
it never leaves AWS. This is key for big businesses and banks under tight rules who need to keep their data within their own AWS space.
Check out this incredible model that supports up to 100K tokens for each prompt, covering both the input and output. Amazon's big bet on this, investing $4 billion for just a slice of the action, speaks volumes. Curious about costs? Take a peek at the model pricing. Some are pay-as-you-go, while others offer guaranteed availability with provisioned throughput. This means you're promised fast, reliable access to the model. Prices are set per hour, and you can opt for a one or six-month term. If you're looking to fine-tune models, you'll need this provisioned option.
For more, visit https://www.anthropic.com/.
This revision maintains a conversational tone and explains the concepts in a straightforward manner without technical jargon.
Let's break down how we can mix up the responses from language models:
• Temperature: This is like adjusting the 'spice level' of the model's replies. A low temperature gives you predictable, common words. Crank it up, and you'll get more creative and surprising words. It's all about how likely the model is to take risks with its word choices.
• Top K: Imagine you have a bag of your favorite words. 'Top K' decides how many words from the top of this bag we consider before making a choice. It's like having a list of favorites and only picking from the best.
• Top P: This is a bit like 'Top K', but instead of a fixed list, it picks words until their combined chance of appearing reaches a set limit. So, it's more about the odds than the rankings.
Both 'Top K' and 'Top P' work with the Temperature setting to fine-tune the randomness of the model's answers.
Now, about setting up our system:
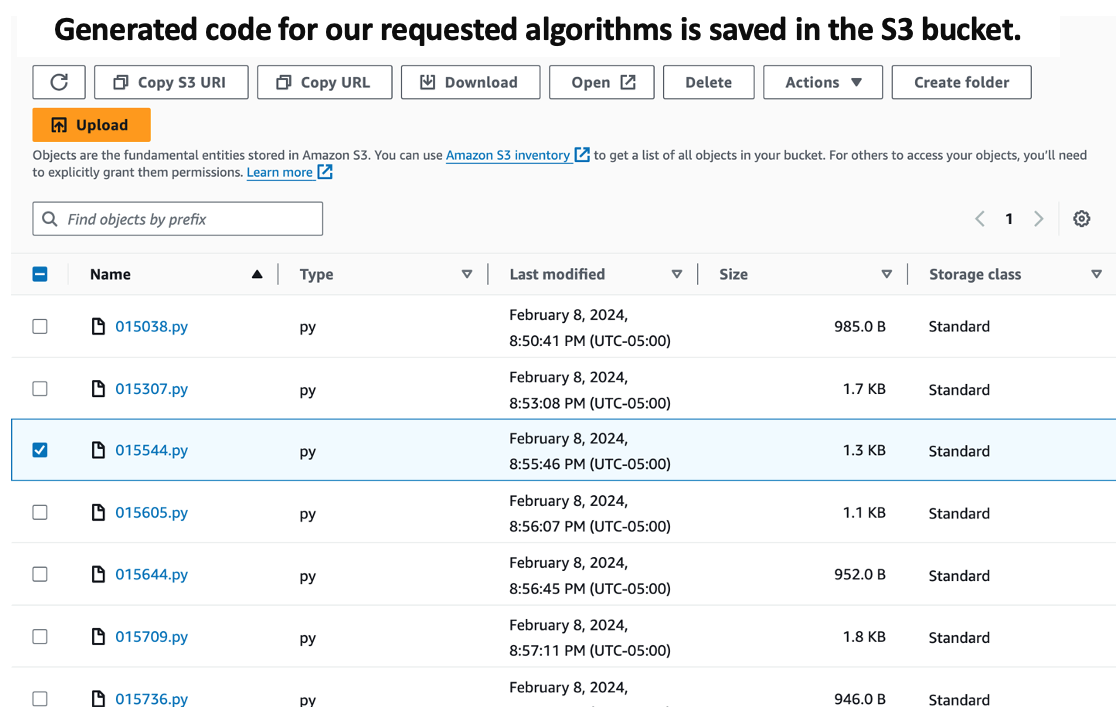
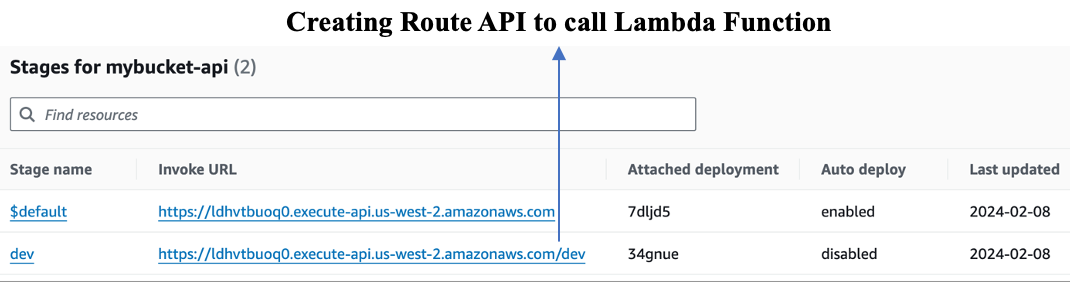
We're building a digital pipeline. It starts with an API Gateway, which is like the entrance for our app's requests. These requests knock on the API Gateway, which then signals a Lambda function (that's our middleman) to fetch what we need from the Bedrock model. Once Lambda has the goods, it drops them in an S3 bucket for storage. In our project on 'Code Generation', we're like directors. We tell Bedrock the script: what code to write, in which language, and Lambda makes sure it's stored nicely in our S3 'warehouse'.
The API Gateway isn't just a door; it's the whole welcome mat, receptionist, and guide for data and services. It's what ties our serverless setup together, letting AWS handle the heavy lifting while we focus on building great things.
Setting it up is a breeze. Create a bucket in S3, pick HTTP API in API Gateway, and add the routes. These routes are like direct lines to the Lambda function, ready to be dialed. Once we've set the stage with our methods and routes, we deploy it and let the magic happen." For more on the OpenAI tokenizer platform, visit here.
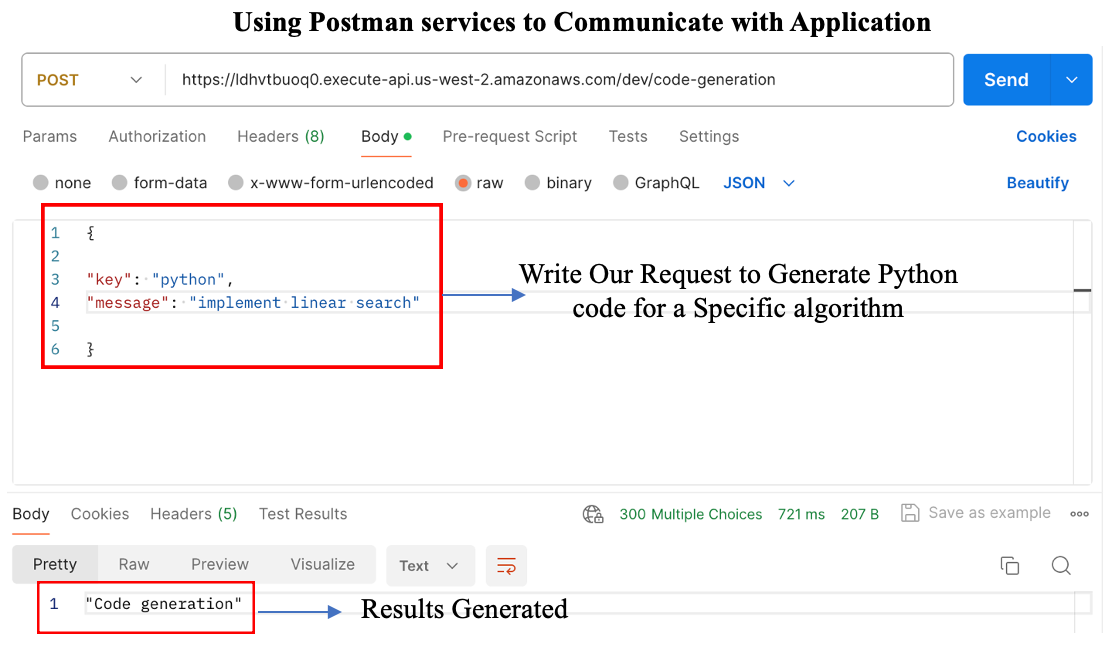
You can now set up your production environment with various APIs.
It's designed so you can easily call a Lambda function and save the results to S3. Just take the URL and use it in the Postman app as a POST request to hit the endpoint you set up for your routes.
Think of it as a mailbox where you send data structured in a 'message and key' format. When Postman confirms the code generation, that's success! But, don't forget to keep boto3 updated to the newest version; this helps avoid any hiccups in code generation. Boto3 can be bundled up as a 'layer' to give your Lambda function more coding muscle.
Here's a quick guide to packaging the latest boto3 for use as a Lambda layer:
#Create a directory for the layer:
mkdir boto3_layer
cd boto3_layer
#Set up a new Python directory and activate a virtual environment:
mkdir python
python3 -m venv venv
source venv/bin/activate
#Install the latest version of boto3 into the Python directory:
pip install boto3 -t ./python
#After installation, turn off the virtual environment:
deactivate
#Compress the Python directory into a zip file:
zip -r boto3_layer.zip ./python
#Finally, clean up by removing the virtual environment directory:
rm -r venv
With this layer ready, you can attach it to your Lambda function and enhance its capabilities.
"Serverless Code Generator with AWS Lambda and Bedrock AI"