





Efficient Meeting Digest: Automating Summary and Task Extraction with AWS
The project focuses on summarizing text from meeting notes. Imagine you've just finished a meeting, and instead of re-reading the long notes, you want a quick summary of the key points. That's the aim of this project. Additionally, it can identify who attended the meeting and highlight the tasks assigned by the project manager. To achieve this, we'll set up a Lambda function and create a route in our API Gateway. The Lambda function will have administrator access to process documents, not just text strings. It will extract information from files uploaded via Postman.
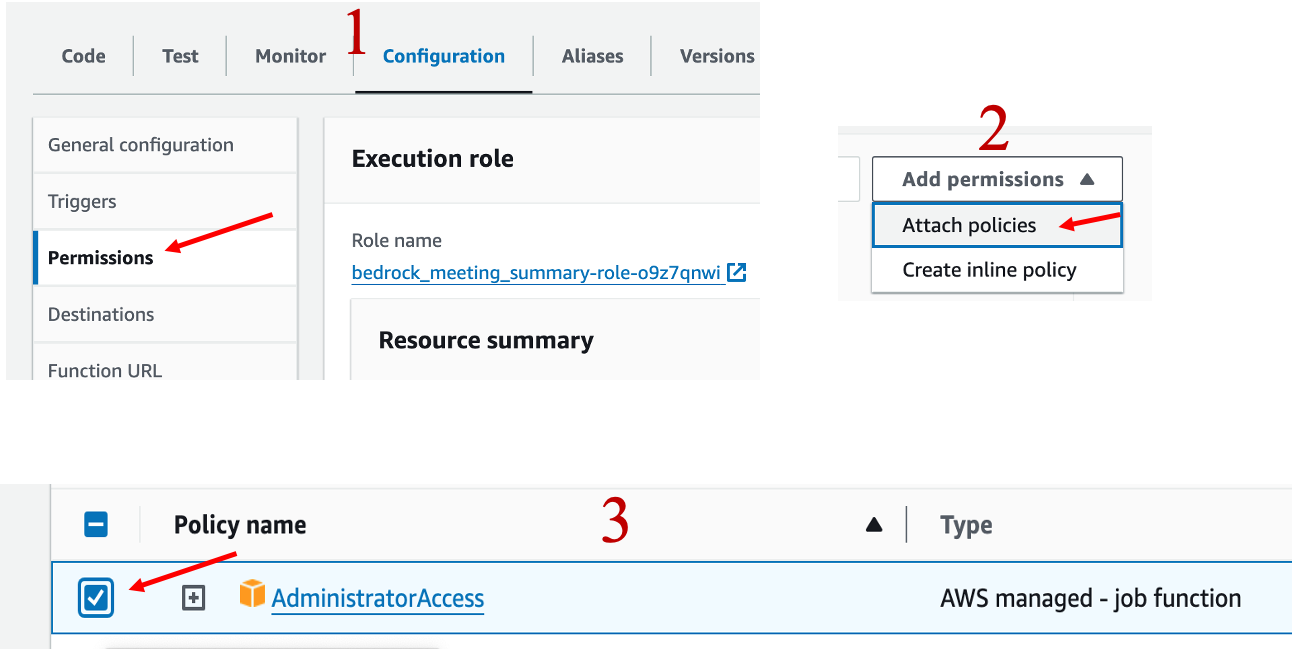
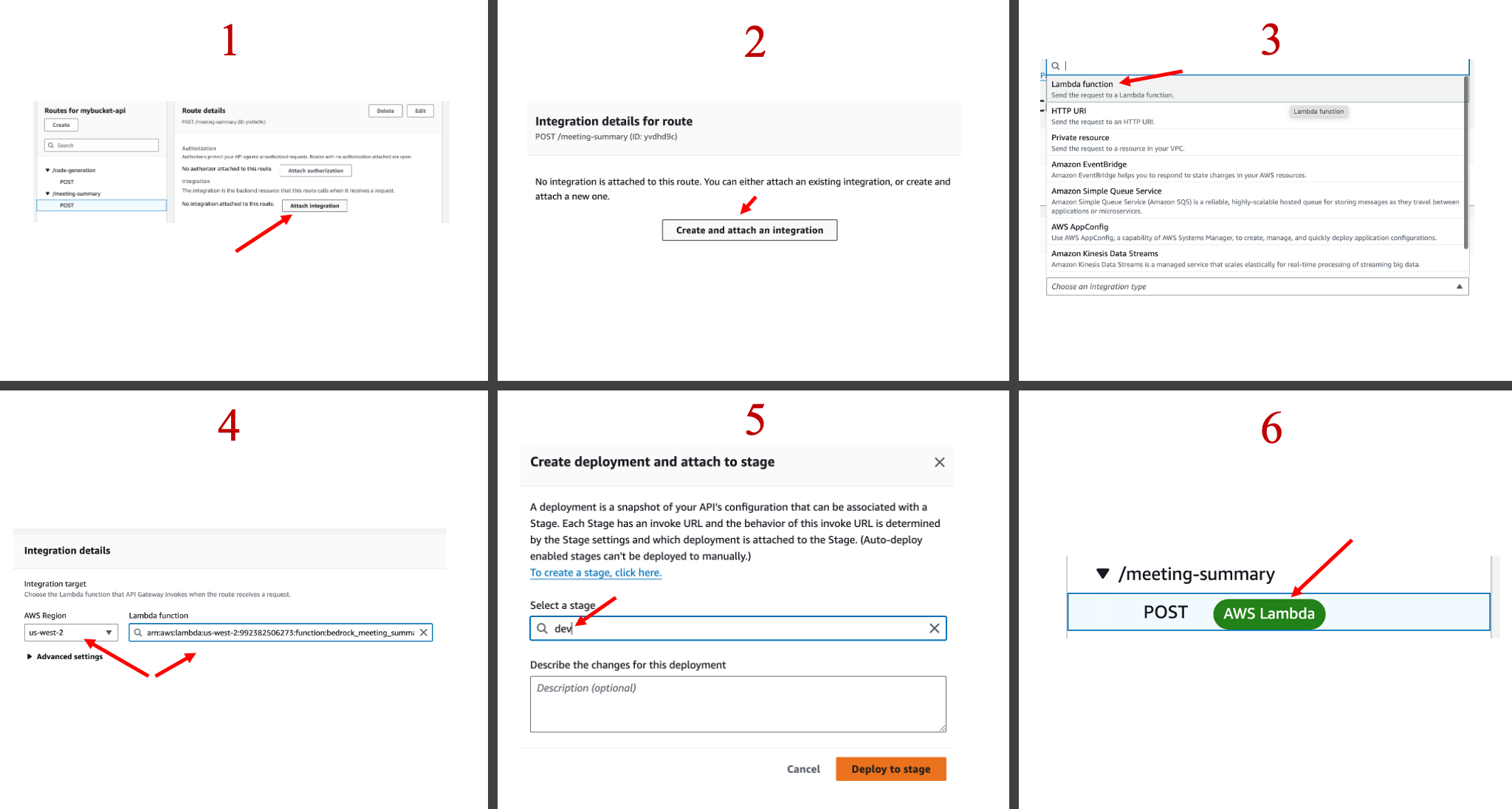
In the API Gateway, we'll attach the new route to the Lambda function. It's important to select the Lambda function from the correct region. Once the setup is complete, we'll deploy it manually to the development branch.
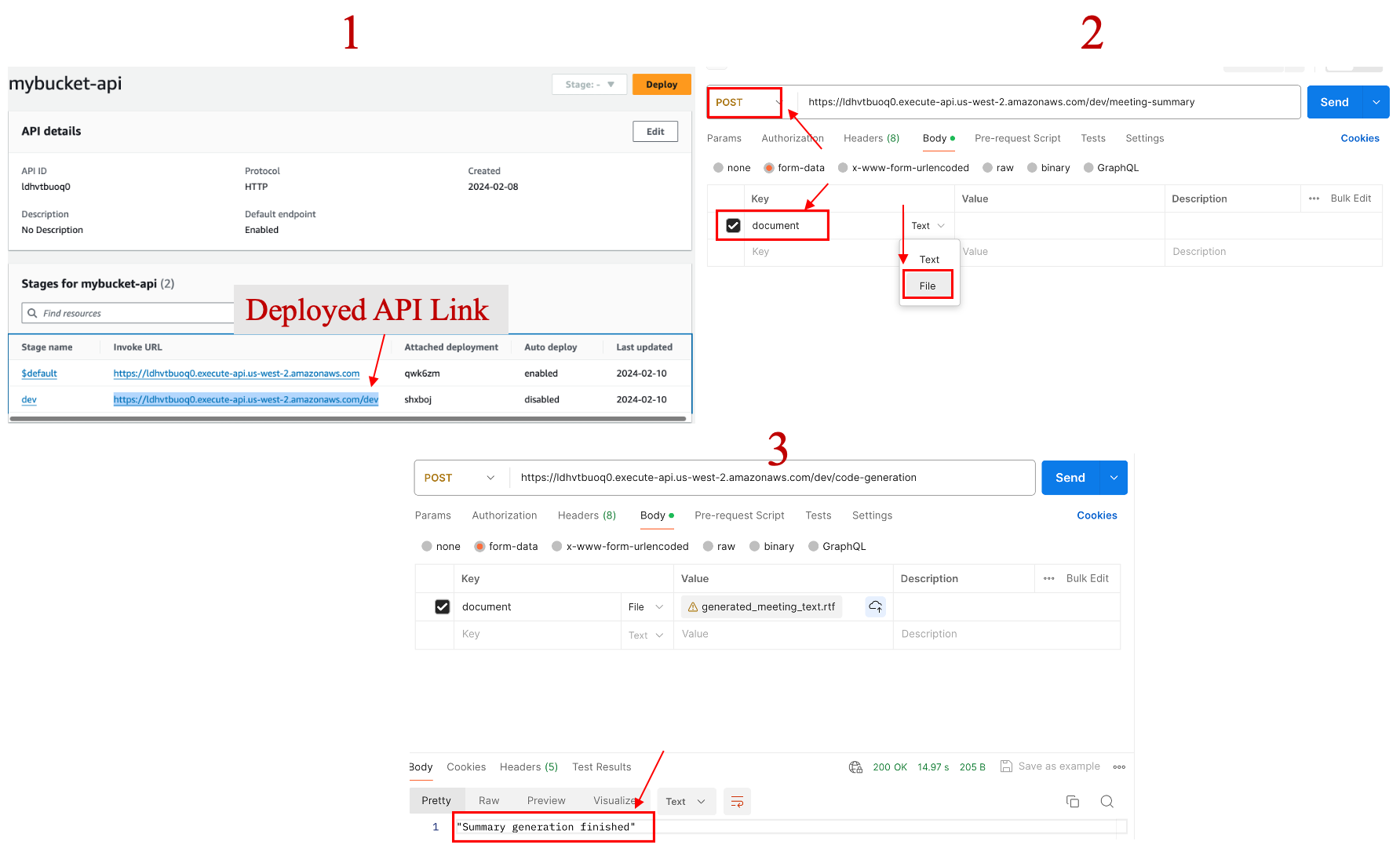
After deployment, we'll copy the development URL from the API Gateway and use it in Postman. Make sure to switch the method to POST and attach your meeting text file. This file could be a fictional conversation generated by AI, designed to summarize the meeting's content.
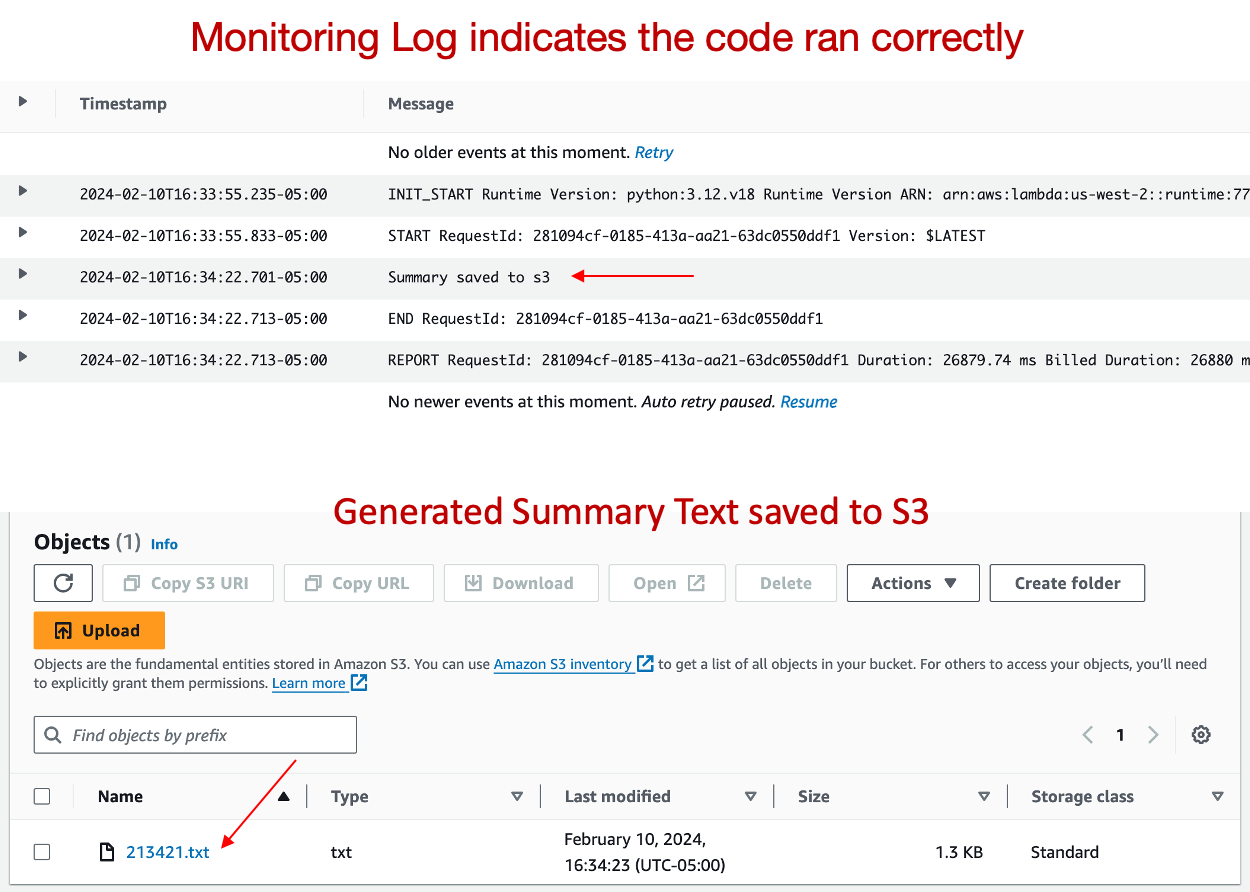
Finally, the summarized points will be saved in our S3 bucket. For instance, we could have a concise summary of a strategic meeting at Microsoft, created from a simulated discussion.
"Automated Meeting Insights Extractor"
Result: AI-Powered Summary and Attendance Extractor

import boto3
import botocore.config
import json
import base64
from datetime import datetime
from email import message_from_bytes
def extract_plain_text_from_email(data):
# upload a file the file can have a name,
# It can have a type. It can have the content
email_message = message_from_bytes(data)
plain_text_content = ''
#Check if the file is made up of multiple distinct parts
if email_message.is_multipart():
for part in email_message.walk():
# if the file part consists of text plain, add it
#to the specified string, then after that add a new line.
if part.get_content_type() == "text/plain":
plain_text_content += part.get_payload(decode=True).decode('utf-8') + "\n"
#If it is not multi-part, then find the text part
# and set the message payload to be the text.
else:
if email_message.get_content_type() == "text/plain":
plain_text_content = email_message.get_payload(decode=True).decode('utf-8')
return plain_text_content.strip() if plain_text_content else None
################################################################################
#The second function is to generate summary from bedrock,
#Then save it to S3 and the lambda handler itself
def summarize_content_using_bedrock(content: str) -> str:
bedrock_prompt = f"""Human: Summarize the following meeting notes: {content}
Assistant:"""
request_payload = {
"prompt": bedrock_prompt,
"max_tokens_to_sample": 5000,
#make the model deterministic
"temperature": 0.1,
#the sequence to look at that are the most probable
"top_k": 250,
# top P works hand in hand with top K
# about the randomness and diversity of the responses
"top_p": 0.2,
"stop_sequences": ["\n\nHuman:"]
}
#Attach Boto3 layer
try:
bedrock_client = boto3.client("bedrock-runtime", region_name="us-west-2", config=botocore.config.Config(read_timeout=300, retries={'max_attempts': 3}))
bedrock_response = bedrock_client.invoke_model(body=json.dumps(request_payload), modelId="anthropic.claude-v2")
response_body = bedrock_response.get('body').read().decode('utf-8')
response_json = json.loads(response_body)
summary_text = response_json["completion"].strip()
return summary_text
except Exception as e:
print(f"Error generating summary: {e}")
return ""
################################################################################
def store_summary_in_s3(summary, bucket_name, object_key):
s3_client = boto3.client('s3')
try:
s3_client.put_object(Bucket=bucket_name, Key=object_key, Body=summary)
print("Summary stored in S3 successfully.")
except Exception as e:
print(f"Error storing summary in S3: {e}")
################################################################################
# lambda handler is the reserved function for AWS Lambda
# This function is calling previous functions
def lambda_handler(event, context):
# thwevent is raw base64 encoded file recived from postman
#So decode it
base64_encoded_body = event['body']
decoded_email_body = base64.b64decode(base64_encoded_body)
extracted_text = extract_plain_text_from_email(decoded_email_body)
#So if text was none, return a 400 Error code to Postman
if not extracted_text:
return {'statusCode': 400, 'body': json.dumps("Failed to extract text from email.")}
#call the bedrock
summary_result = summarize_content_using_bedrock(extracted_text)
if summary_result:
timestamp = datetime.now().strftime('%Y%m%d%H%M%S') # Format: YYYYMMDDHHMMSS
s3_object_key = f'summary-output/{timestamp}.txt'
s3_bucket_name = 'mybucket-textgenerate'
store_summary_in_s3(summary_result, s3_bucket_name, s3_object_key)
else:
print("Failed to generate summary.")
#return a 200 Error code to Postman
return {'statusCode': 200, 'body': json.dumps("Summary generation completed successfully.")}